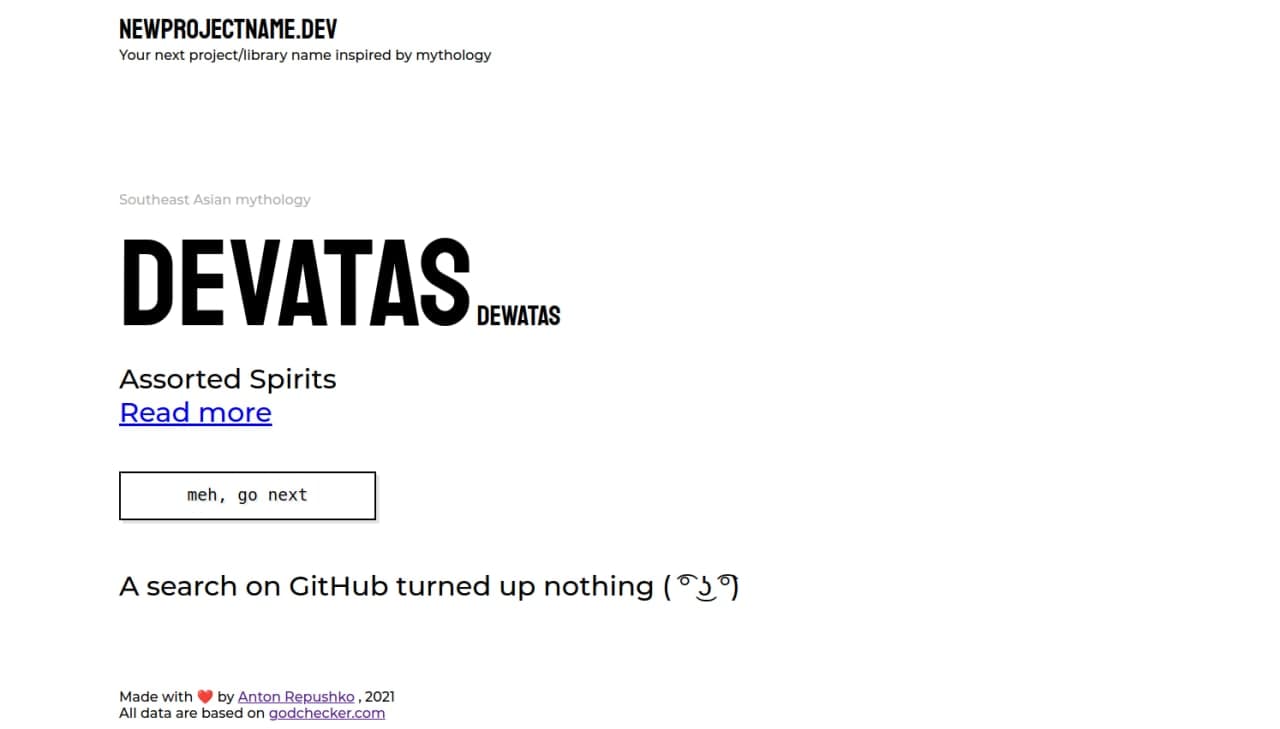
https://newprojectname.dev
Есть забавная традиция называть проекты/библиотеки именами различных мифических существ и божеств. И у меня давно лежала идея хелпера по подбору таких названий, но реализовал её только сейчас.
Я напарсил самый большой список названий божеств из 43 пантеонов, что дало 4096 уникальных имён (и 9000 если считать все алиасы). Ну а чтобы избежать коллизий, проект на лету ищет эти имена в названиях репозиториев на Гитхабе и показывает топ-результаты.
Из интересной инженерии: проект на Svelte, имеются исходники. Внутри есть база на 1Мб сырого json’a, которая затаскивается в общий бандл приложения и ужимается до 150кб. И из-за этого хака всё успешно хостится как статика на Digital Ocean’e за 0.00$ в месяц. Дизайн тоже корявенько делал я. Запросы к Гитхабу — клиентские, лимиты запросов — тоже на клиенте. Легчайшая поддержка.




.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)