Дневник соревнования OpenEDS 2020
Мы со Святославом Скобловым 2 месяца решали OpenEDS 2020 Challenge, где в одном треке заняли первое место, а во втором восьмое. Про второй трек тут не будет, потому что он скучный и не очень интересный. И ещё нас изредка консультировал Вова Михеюшкин по всяким CV-вопросам. Может быть кому-то тоже будет интересно почитать, как проходят соревнования по ML.
Про соревнование
На основе датасета OpenEDS2020, собранного Facebook Reality Labs, запустили два трека. Оба связаны с VR/AR, Oculus и всем таким. Треки шли в рамках воркшопа к ECCV 2020.
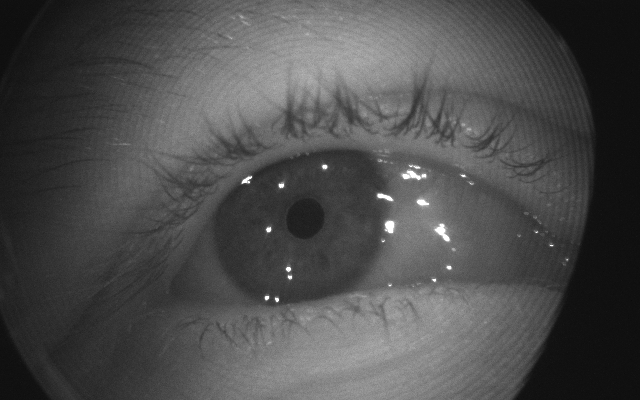
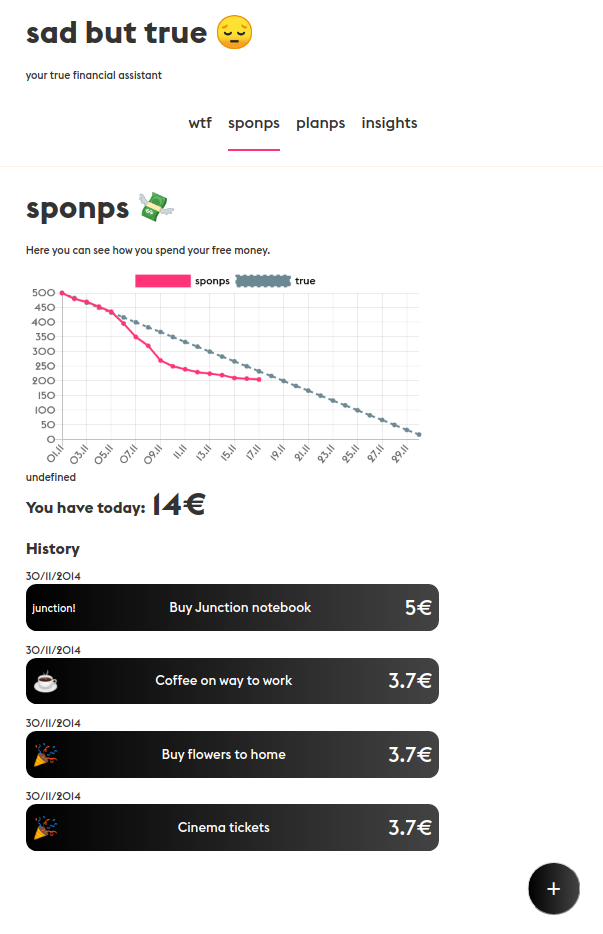
В первом треке даны последовательности по 100 (трейн) и 55 (валидация) фотографий глаз с gaze-векторами каждого кадра. Представьте, что вы умеет стрелять лазерами из глаз. Вот отнормированный вектор из вашего зрачка до объекта на VR/AR экране и есть gaze-vector.
Частота записи последовательности — 100Гц. В тесте были те же последовательности по 50 кадров, но уже без настоящих векторов. Общая задача — научиться предсказывать по 50 кадрам последовательности в тесте следующие 5 кадров (т.e. 50мс). Нужно это для foveated rendering.
Во втором треке нужно было сегментировать части глаза (бэкграунд, склеру, радужку и зрачок) по кривой разметке 5% данных в каждой последовательности из 200 кадров. Многие (по отзывам других участников) боролись именно с кривой разметкой, мы же начали решать второй трек за 2 недели до конца и не слишком преуспели, хотя разрыв между топом очень маленький. Важнее и интереснее для нас был именно первый трек.
Технические особенности
Соревнование проводилось на платформе EvalAI. Там можно скрывать свои сабмиты, но перед этим на какую-то долю секунды они попадают на общую таблицу. Поэтому было решено написать своего бота, который бы мониторил изменения лидерборда, генерировал красивые картинки и присылал их в наш общий диалог. С помощью него мы могли трекать и отслеживать настоящих лидеров, а не те результаты, которые были показаны вручную.
Был только 1 сабмит в день, каждую ночь предыдущая возможность сабмита сгорала.
Своего железа у нас было не очень много, поэтому мы время от времени арендовали машины на vast.ai. Потратили на это около 230 долларов за 2 месяца соревнования.
Дневник
1 июня
Создан чат в Телеграме, начали разбираться в предметной области, с платформой, читать правила. Выяснили, как части глаза называются на английском. Создали репозиторий на Гитхабе и настроили всем доступы.
3 июня
Выкачиваются данные, визуально посмотрели gaze-вектора. Появляется идея классическими CV-методами поисков контуров искать зрачок на изображении и смотреть на изменение его положение внутри склеры. Разбираемся в типах движения глаза (саккады, скольжения, статичное положение и т. д.). Наконец-то понимаем вообще в чём суть трека.
4 июня
Нашли pupil-labs, с помощью оборудования которых Facebook генерировал свой датасет. Ничего полезного, но очень интересно.
Научились находить зрачок обычными CV методами. В итоге это потом использовалось только в визуализациях.
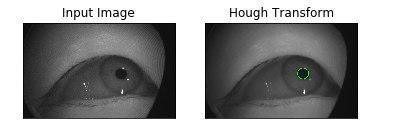
Пытались добавить ещё всяких контуров, но ничего не получилось.
Важное решение: посчитали правильным разделить пайплайн на две части: gaze-estimator (модель, которая по кадру предсказывает его gaze-вектор) и gaze-predictor (модель, которая по истории gaze-векторов предсказывает gaze-вектора следующих 5 кадров).
6 июня
Начали визуализировать вектора, чтобы посмотреть на всю последовательность целиком. Нам нужен gaze-predictor, но насколько сложным он будет? Если в данных в основном статичное положение глаза, то тогда сложная модель тут не нужна (так в итоге и оказалось).
Где-то тут было решено для обучения эстиматора (модели, которая будет по кадру предсказывать gaze-вектор) использовать аугментации. Но проблема в том, что при изменении изображения нужно будет менять и изначальный вектор: вращаешь изображение -> вращаешь вектор. Решили патчить albumentations.
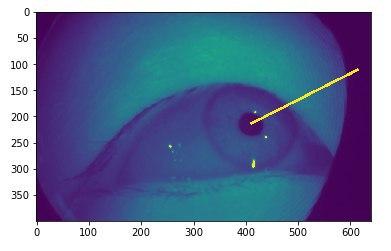
11 июня
Начали гонять первые модели, оптимизировать параметры. Стали разбираться с предиктором. Попробовали всякие стандартные штуки для форкаста временных рядов типа prophet, но они предсказуемо не зашли из-за специфики данных: нельзя вытащить сезонность (которой нет), другие фичи вроде дней недели, времени и прочего, что активно эксплуатируется в таких местах.
Обучили первый resnet для эстиматора.
12 июня
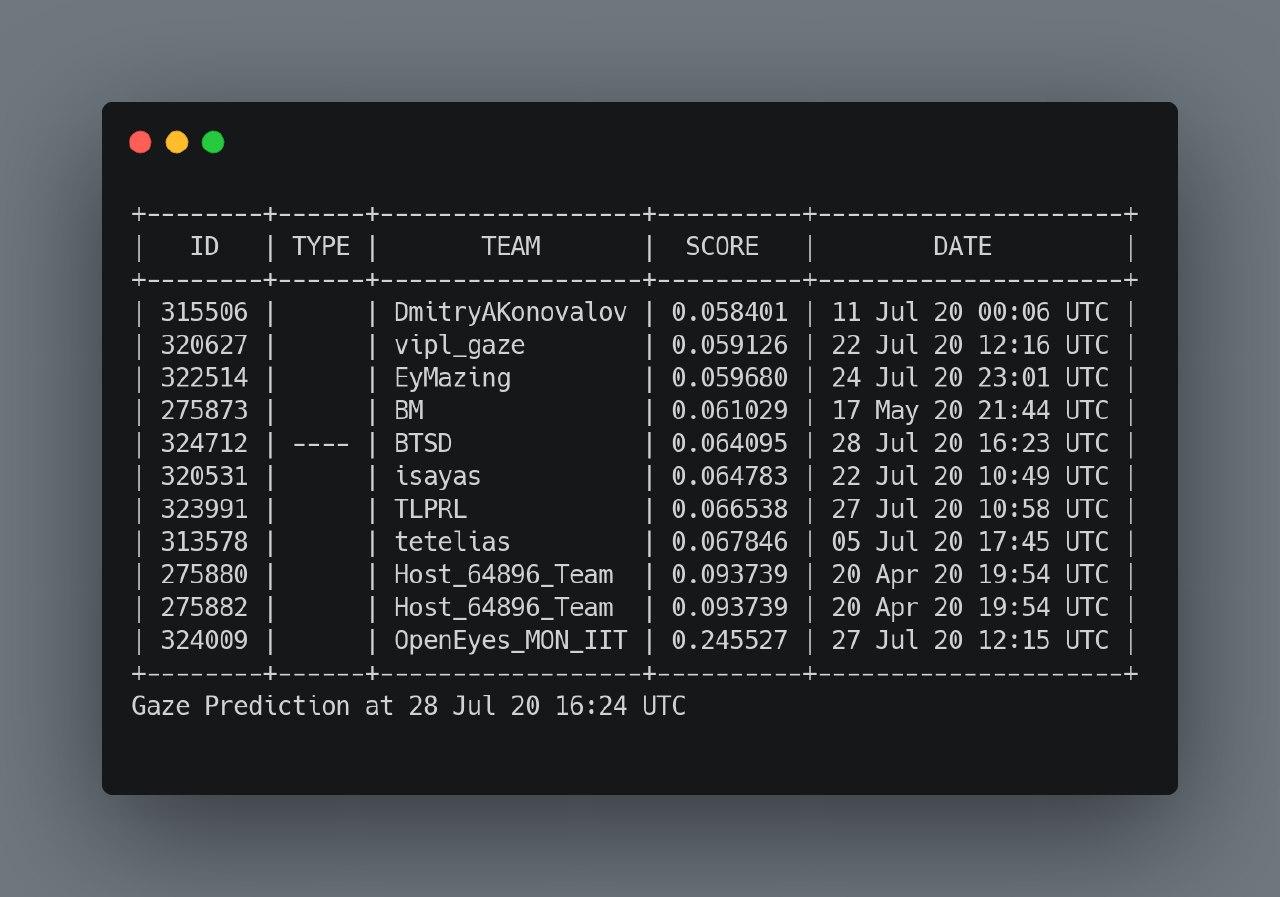
Скор первого трека: 0.1556
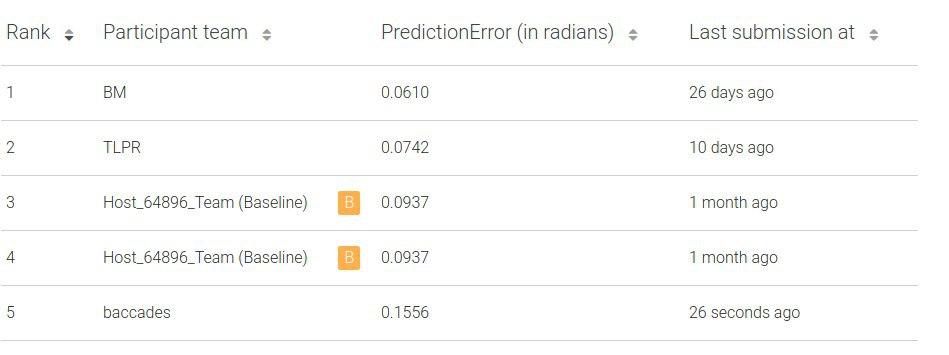
Начали глубже разбираться с метрикой и сравнивать предикты модели с реальными данными, чтобы понять, где косяк. Настроили честную локальную валидацию эстиматора.
15 июня
Скор первого трека: 0.0786
Засабмитили улучшенную модель (VAR поверх хорошего эстиматора).
Это приблизило нас к остальным на ЛБ.
16 июня
Скор первого трека: 0.0747
Написан и запущен Big Brother — бот, который следит за ЛБ. С этого момента до конца соревнования он работал с одним перебоем на полдня, после без ошибок.
Засабмитили скользящее среднее по 5 последним кадрам.
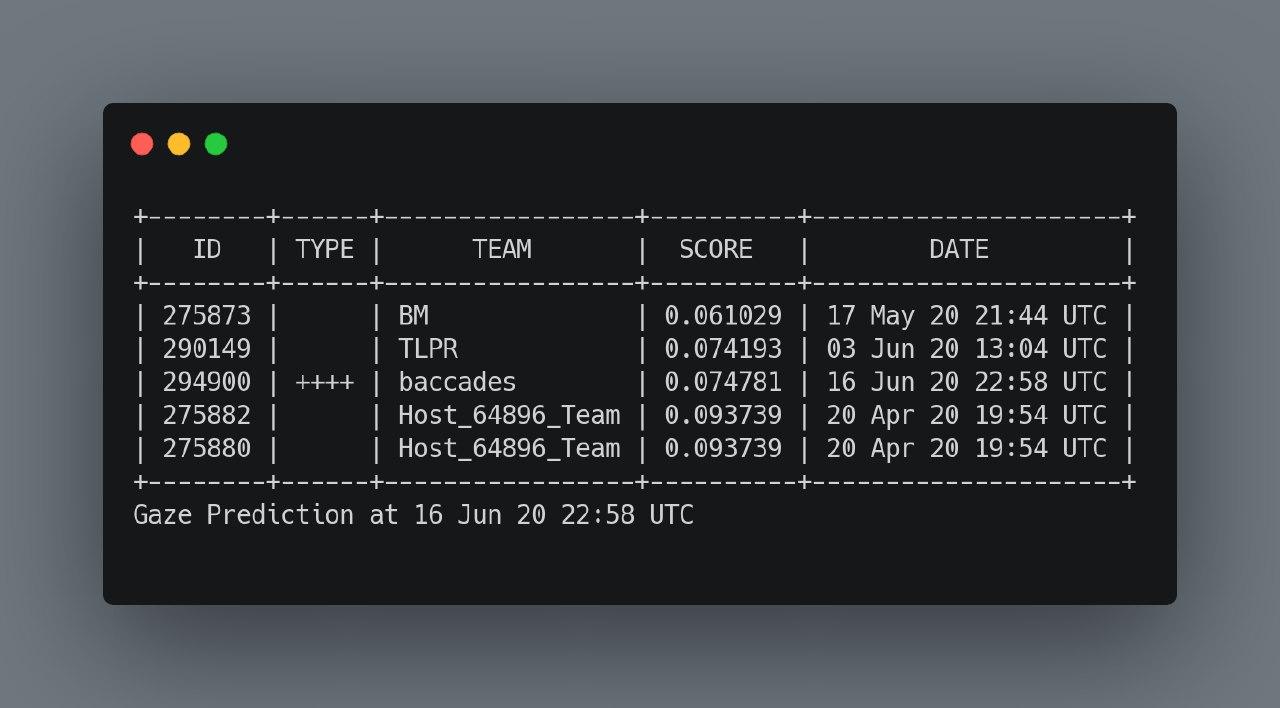
17 июня
Посмотрели на статические генераторы таких данных (NVGaze и UnityEyes). В итоге для сореванования их так и не использовали.
22 июня
Предикт эстиматора очень грязный: колбасит вектора между кадрами и получается, что между ними как будто бы сильное движение глаза.
28 июня
Подумали, что было бы классно научиться группировать авторов одних и тех же последовательностей (количество участников при сборе датасета на порядки меньше числа последовательностей), чтобы вытаскивать оттуда какие-то фичи специфичные для конкретного участника. Эту идею так и не доделали.
Начали думать про классическое CV снова: хотели вытаскивать крайние точки глаз и прочее.
Обучили LSTM для предиктора. Сработало чуточку хуже средних по 5 кадрам.
29 июня
Закончили патчить albumentations.


1 июля
Начали подозревать, что в тесте всё таки в основном статика. И что самый большой буст тут даст улучшение эстиматора, а не предиктора.
Нафигачили для эстиматора аугментаций.
4 июля
Скор первого трека: 0.0613
Стали думать, как сделать интереснее предиктор. Взяли потыкать darts — это такой враппер над всякими стандартными моделями для форкаста.
Запустили старый метод среднего по кадрам (или какую-то оч простую эвристику) над данными нового эстиматора. Очень сильно улучшились.
5 июля
Скор первого трека: 0.0570
Выучили пачку effnet’ов (до этого был resnet). Начали дробить на фолды и мешать предикты с разных фолдов.
Сняли тачку на vast.ai.
Посмотрели на тестовые данные на основе более-менее нормальных предиктов эстиматора. Оказалось, что какая-то динамика в последних 10 кадрах последовательности есть всего в 600-700 последовательностях из 6400.
Засабмитил старые методы предикта на среднем фолдов effnet’а. Почти до самого конца это было нашим лучшим результатом и первым местом на ЛБ.
9 июля
Обучили mobnet. Стали экспериментировать с предиктором: ExponentialSmoothing, VAR, ARIMA и т. д.
Методы ничего не докинули, а некоторые и ухудшили скор относительно просто среднего.
Скор самого предиктора при этом был очень хороший, около 0.000400+ на кадр по их метрике.
Первый раз открыли данные второго трека, порисовали маски.
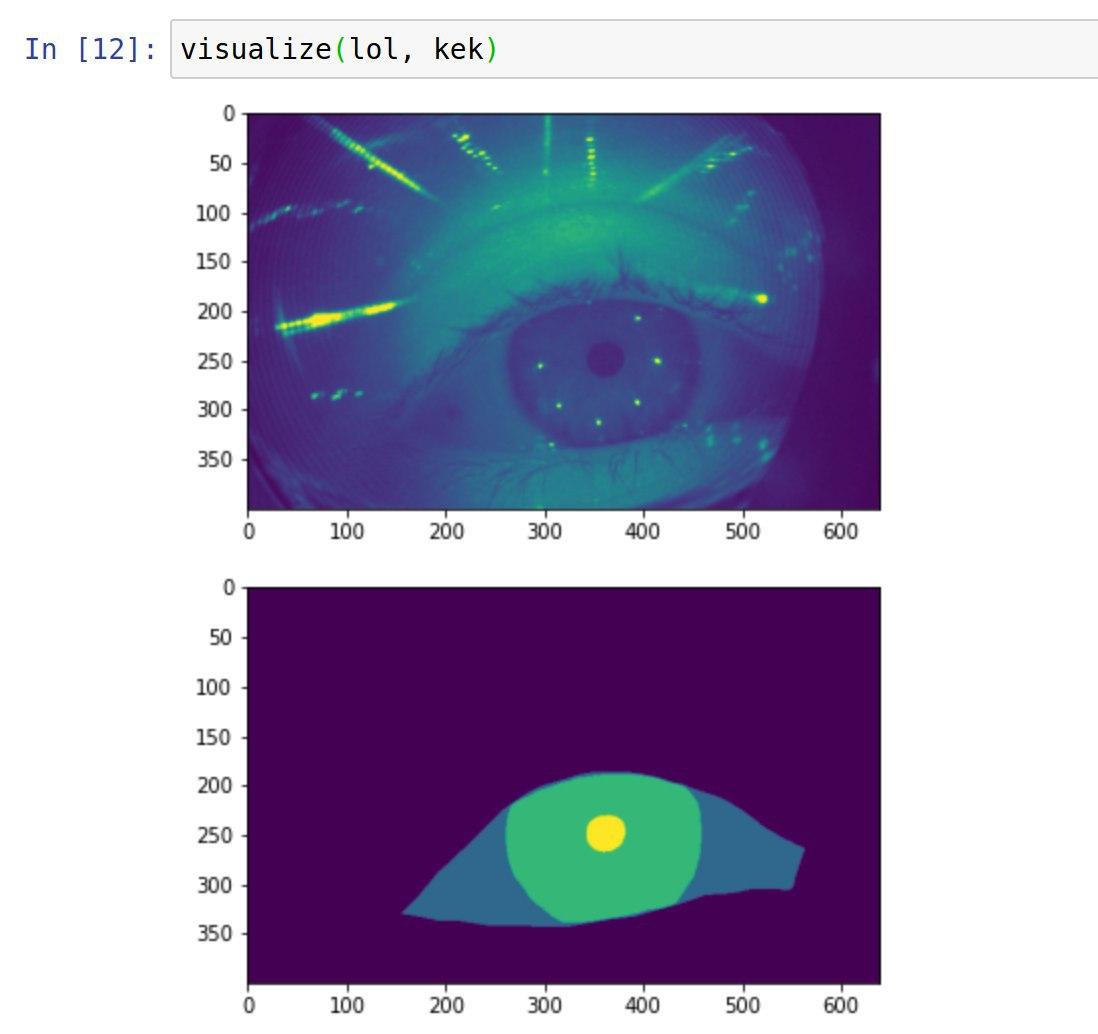
10 июля
Засабмитили скользящее среднее по 3 кадрам на куче разных фолдов — не сработало.
Постарались достраивать вектора регрессией. Тоже не сработало.
11 июля
Начали играться с фильтрами над сигналом, чтобы сгладить разницу предиктов эстиматора между соседними кадрами. Получалось хорошо, использовали фильтр Савицки-Голая. Кажется, что всякие неровности эстиматора очень красиво сглаживаются.
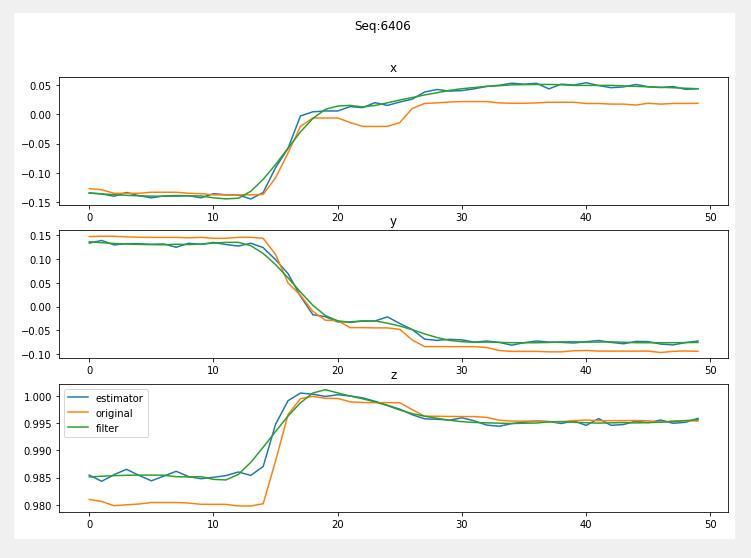
12 июля
Разбирались с предиктором. Выяснили, что наша регрессия багованная и искали ошибку в разнице валидаций друг у друга. Нашли. Смотрели глазами на фильтрованные предикты и думали, что делать дальше.
14 июля
Нарисовали красивые картинки градиентов по разным осям между двумя соседними кадрами по предиктам на всём тесте. Выяснили, что у нас действительно всё — статика. Поэтому опять же нет смысла во всяких сложных моделях предиктора.
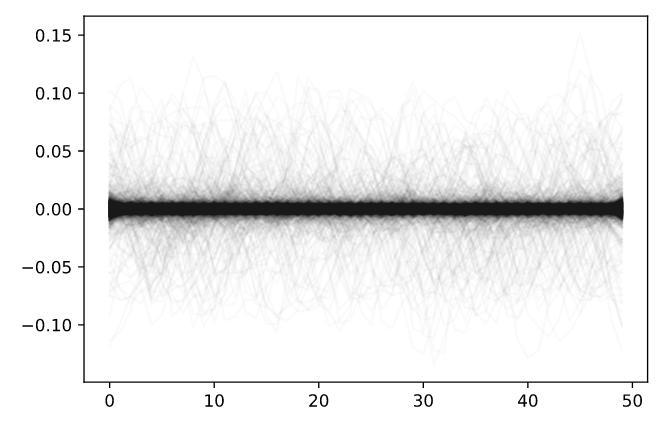
Выяснили, что локальная метрика эстиматора напрямую коррелирует с результатами на ЛБ и что результат одного хорошего фолда лучше, чем его же со смесью фолдов чуть-чуть хуже. Опять упёрлись в то, что надо дотюнивать эстиматор. Вернулись к resnet’у.
14 июля — 23 июля
Скор первого трека: 0.0552
Разбирались с сегментацией, удивлялись кривой разметке, сложным случая с закрытыми глазами и т. д.
Вытюнили 1 фолд для эстиматора до ошибки 0.000197 (в 3 раза лучше прошлых). В предиктор засунули простую эвристику: если статика, то скользящее среднее по 2 последним кадрам, а если была динамика в последних 5 кадрах, то добавляем градиент дальше до упора (из-за особенностей движения глаза, там бОльшая часть движений — линейная).
23 июля — 29 июля
Тюнили и думали над сегментацией. Смотрели на то, как нам применить синтетические данные в сегментаци. Генерировали синтетику.
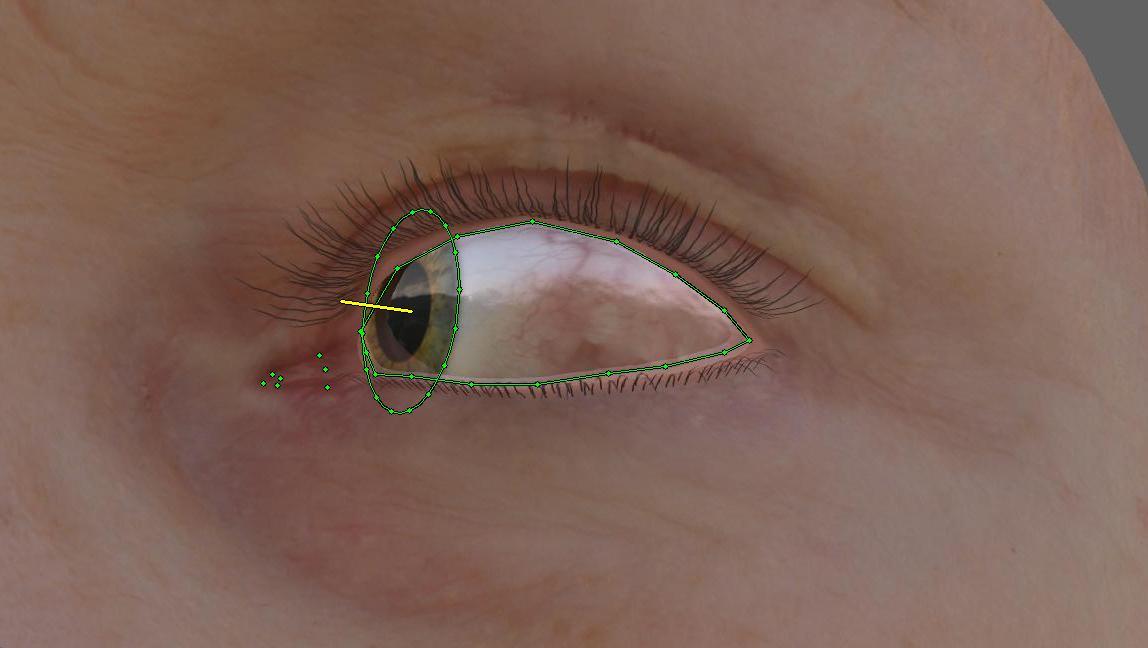
Из интересного: один сабмит пропустили, потому что кое-кто заснул от усталости и не слышал звонков с просьбой прислать данные. Два сабмита в два дня были сделаны за 30 и 20 секунд до сгорания.
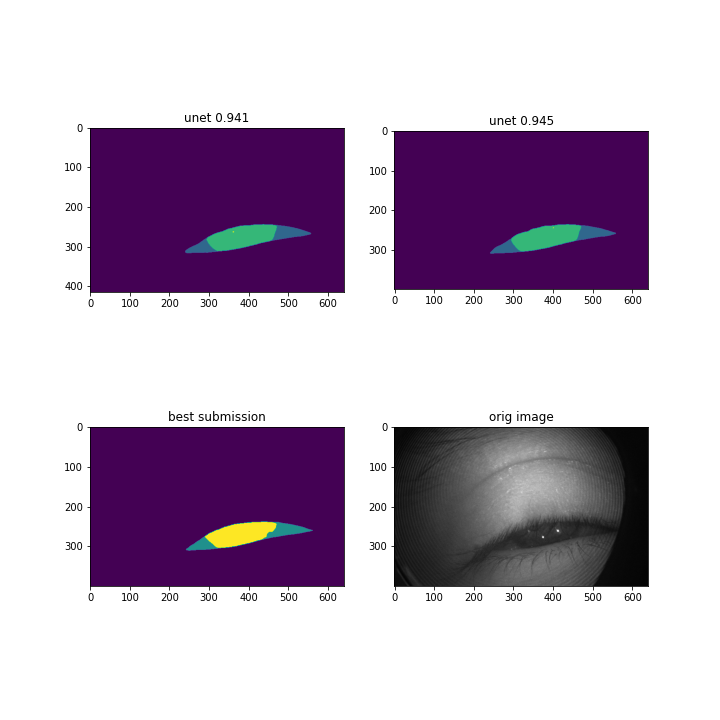
30 июля — 31 июля
Скор первого трека: 0.0537
Смотрели и думали над всякими сложными случаями в сегментации
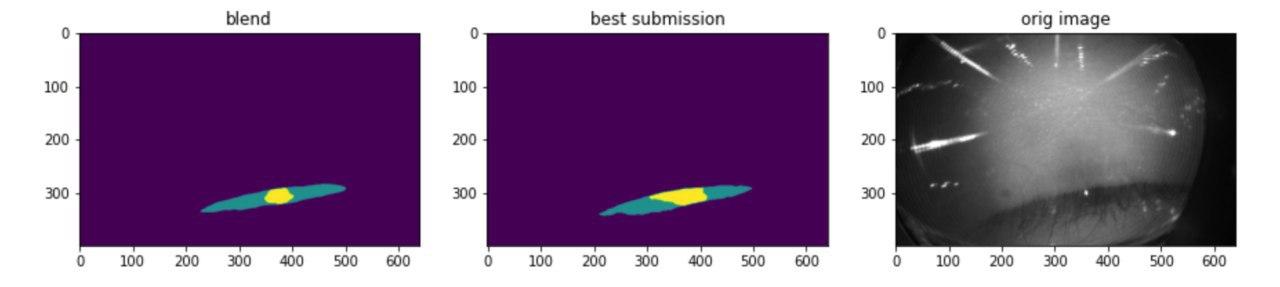
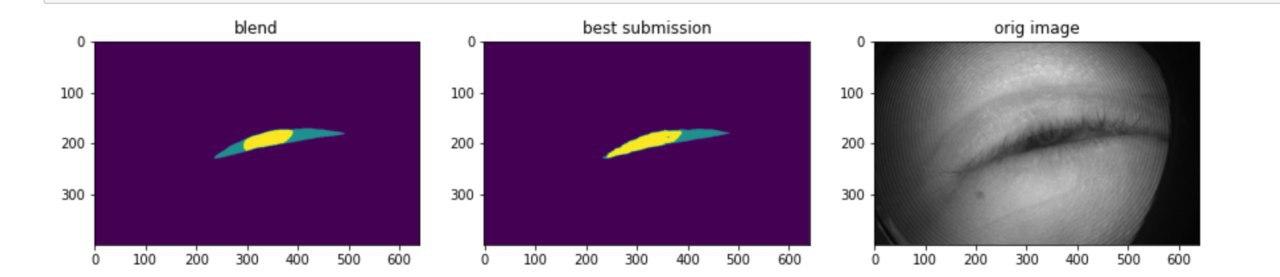
По первому треку доучили остальные бленды эстиматора, сблендили и засабмитили. Так и осталось нашим лучшим результатом.
По сегментации остались на 8ом месте.
Что хотели попробовать, но не попробовали
- Не использовали никакую синтетику, а скорее всгео надо было бы. Можно и в обоих треках
- Надо было учить LSTM на чистых данных (в том числе из теста и из трейна) и сразу на векторах. Наши эвристики в итоге были по каждой оси отдельно